Grafana Dashboard using Telegraf with additional plugins
-
Ok so steps i've performed so far. I think there are bugs in the latest git repository.
docker exec -it influxdb /bin/sh influx delete --bucket pfsense --start '1970-01-01T00:00:00Z' --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="tail_dnsbl_log"' influx delete --bucket pfsense --start '1970-01-01T00:00:00Z' --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="tail_ip_block_log"' influx delete --bucket pfsense --start '1970-01-01T00:00:00Z' --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="gateways"' --org-id [id] influx delete --bucket pfsense --start '1970-01-01T00:00:00Z' --stop $(date +"%Y-%m-%dT%H:%M:%SZ") --predicate '_measurement="interface"' --org-id [id]If your WAN config looks like mine with ipv4 and ipv6 enabled, then you end up with a problem with the gateways telegraf lines as igb0 exists twice. Gateways used to use gateway_name probably for this reason. It means that the tag grouping won't work if you have ivp4 and ipv6 enabled.
So i've had to change telegraph_gateways.php to include gateway_name and then adjust the grafana dashboard to use gateway_name instead of interface. (basically reverting it back to how it worked on the previous revision.
Next issue is telegraf is nolonger exporting the interface measurement.
Looks like this changeset replaced "interface" with "gateways". Looks like a copy paste issue to me.
github diffAs a result of this problem, none of the interfaces show up correctly on the dashboards.
The interface summaries work with the old version of telegraf_pfinterface.phpFinal note, is this dashboard now requires a 1440p monitor to view everything without horizontal scrolling. Would be nice if it would display on 1080p monitors
-
@wrightsonm
This is the dashboard working once again for me: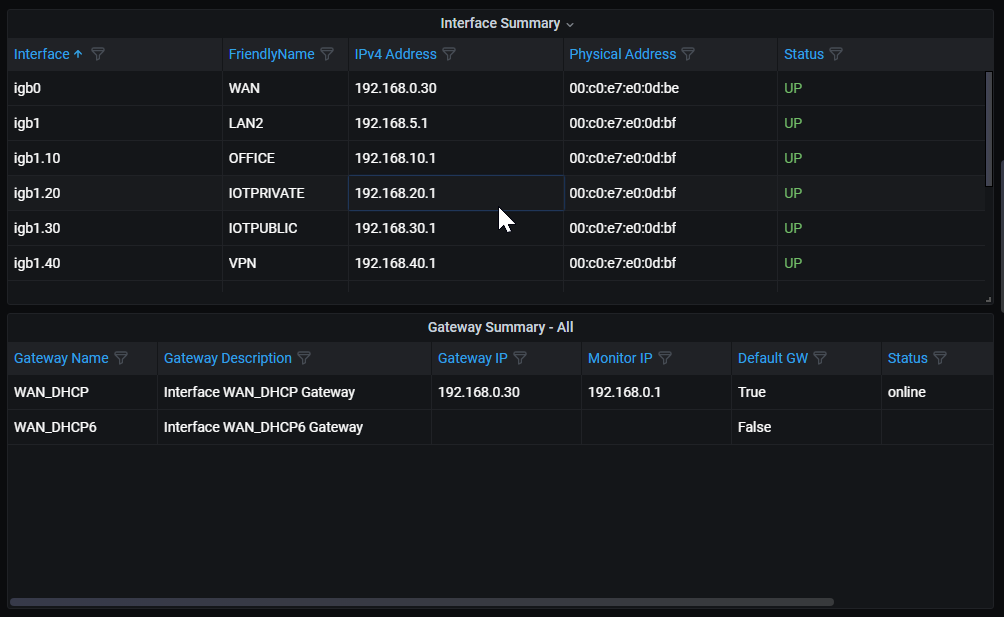
telegraf --test --config /usr/local/etc/telegraf.conf
Grafana Gateway Variable changed back to:
SHOW TAG VALUES FROM "gateways" WITH KEY = "gateway_name" WHERE "host" =~ /^$Host$/Modified plugins:
telegraf_gateways.php.txtReverted plugin:
telegraf_pfinterface.php.txtModified dashboard:
grafana.json.txt -
@wrightsonm said in Grafana Dashboard using Telegraf with additional plugins:
with ipv4 and ipv6 enabled, then you end up with a problem with the gateways telegraf lines as igb0 exists twice
Does this happen for the interface table? If you are willing to troubleshoot this with me, please open a github issue so we don't flood this thread with troubleshooting.
-
@jpetovello This is a pet project I built for use with my homelab and documented to help others. The main prereqs are that you have influx and grafana already set up. I didn't document that since everyone is going to have their systems set up differently. Luckily, there's no shortage of tutorials available online. My recommendation is to get your influxdb and grafana setup, read the github readme, read through this thread, and search the closed issues in the github project.
-
@victorrobellini yeah sure. I've not got any time until Tuesday now. The solution is in the attachments and pictures above. I can raise a Pull Request with the fixes on Tuesday if you like?
-
@wrightsonm I just reread what you wrote. I have no idea how that happened. Thanks for the heads up. I may just merge the 2 scripts since they are doing very similar stuff. I'll take a look this weekend.
Update: I merged the scripts and updated the repo. Everything should be working now.
-
@wrightsonm said in Grafana Dashboard using Telegraf with additional plugins:
Final note, is this dashboard now requires a 1440p monitor to view everything without horizontal scrolling.
Sorry, I run this on either a 4k or an ultrawide 1080p display. If you have it reformatted for 1080p just add the json with a new name and submit a PR.
-
I copied the new scripts for plugin and configured permissions on them (755), imported new dashboard but now I'm not getting any temperatures reading, IP or DNSBL lists, no network interface summary, no Gateway RTT or loss. Any hint what I missed in the upgrade process?
-
@von-papst Got temperatures working (CRLF from M$ messed up script). Still missing lists from pfblocker-ng and interface summary.
-
@von-papst check the CRLF on all the plugins. Then use the telegraf test command to check that there are no errors. Failing that add the debug logging option to telegraf and check the log file. Instructions for the above are on the GitHub readme.
-
@wrightsonm Got pfblocker working, changed queries and added some info. But Gateway RTT and loss still not working.
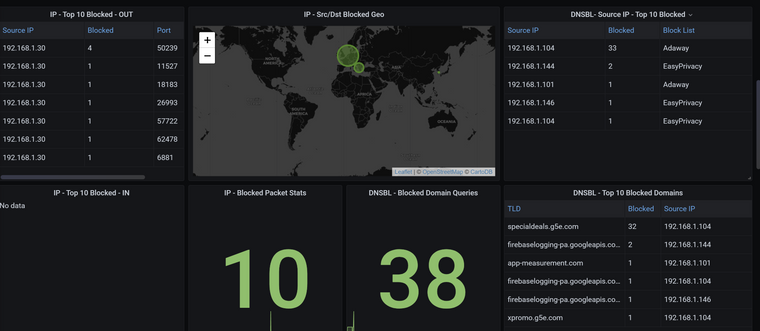
-
@wrightsonm Got everything working now. I needed to modify some queries in the dashboard and added gateways.py script.
-
I'm a bit confused, where do the plugins need to be placed? Am I supposed to upload them to my pfSense install?
-
@jpetovello you should upload them to you pfsense.
-
I think there was some drift between my local system and my repo. I've updated the dashboard JSON. It should work with the updated gateways/interface plugin.
-
@victorrobellini What is your influxdb ram utilisation looking like with the latest set of changes? With the grafana dashboard, my influxdb ram has increased to 12GB. I had to increase the RAM allocation on my docker VM (now at 20GB). I'm going to keep an eye on it.
I think high series cardinality might be related. Will do some investigations. Unfortunately InfluxDB OSS v2 doesn't currently implement the cardinality command (only Cloud version at the moment).
https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/influxdb/cardinality/I also think the logged data shows something port scanning me yesterday which may be related to the big increase in cardinality of the data.
-
I found this neat little command playing around with PowerD options and it seems to be really light and work well for tracking CPU frequency changes.
sysctl dev.cpu.0.freq
Was thinking it would make a nice graph for those are also using PowerD which I would think would be most people but I could be wrong.
I would write this myself but it would just end up getting done better by others in this thread :)
@VictorRobellini what do you think about this, good add?
-
Interesting, I never messed with that, I just turned it on. This is an easy fit and can use the same script as the telegraf_temperature.sh script.
All you need to do is add the following line to the end of the script and build some graphs.
sysctl dev.cpu | fgrep "freq:" | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "temperature,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($7)-1)}'The better way to implement it (which I don't have the time for right now) is to completely rename the telegraf_temperature.sh script to be something like telegraf_sysctl.sh and update all of the commands to output with a similar format and then update the queries and graphs. If you just want to poke around and see what you can get, use the above recommendation.
sysctl dev.cpu | fgrep -e "freq:" -e temperature | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "sysctl,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($6)-1)}' sysctl hw.acpi.thermal | fgrep temperature | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "sysctl,sensor="$4",host="HOST" "$5"="$6"." substr($7, 1, length($7)-1)}'Something like this:
sysctl,sensor=cpu0,host=pfSense.home freq=1900 sysctl,sensor=cpu3,host=pfSense.home temperature=47.0 sysctl,sensor=cpu2,host=pfSense.home temperature=47.0 sysctl,sensor=cpu1,host=pfSense.home temperature=49.0 sysctl,sensor=cpu0,host=pfSense.home temperature=49.0 sysctl,sensor=tz1,host=pfSense.home temperature=29.9 sysctl,sensor=tz0,host=pfSense.home temperature=27.9 -
@victorrobellini said in Grafana Dashboard using Telegraf with additional plugins:
sysctl dev.cpu | fgrep "freq:" | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "temperature,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($7)-1)}'
That worked like a charm, thank you so much.
-
Anyone else having problems with Uptime displaying?
Mine just shows N/A