The delay after enabling CP is very large
-
HI
Teams and all
Why is the delay in pinging the gateway so long when loading a web page?
When loading is complete, the time will return to normalIt's not a wifi/ap problem, because there is no problem using other access points。
All are default configuration
Except the following:
1: Configure the network card
2: Enable CP
3: Disable DNS Resolver and enable DNS forwarderWhat could be the cause of this and how to solve it?
Thanks!
This is my systeminfo:
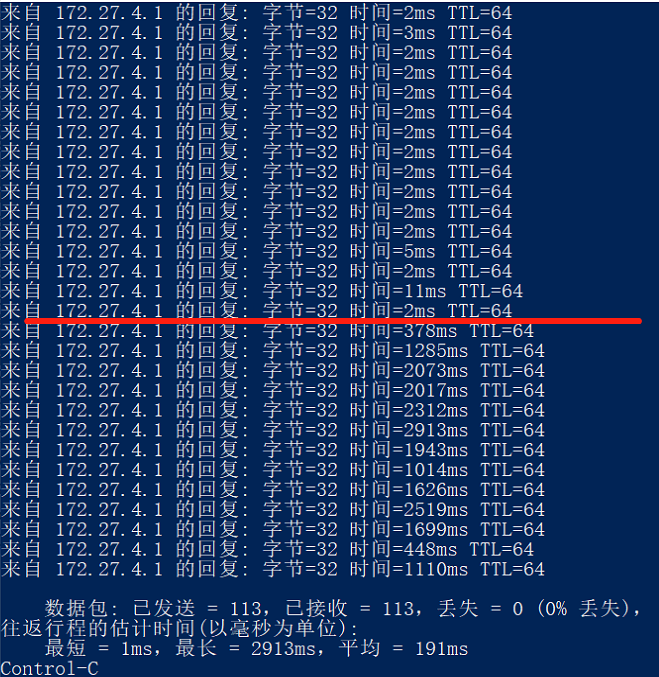
Client ping gateway(lan of pfsense) info:
Below the red line is the ping time for loading the web page
DiagnosticsLimiter Info
Limiter InformationLimiters:
02008: 300.000 Kbit/s 0 ms burst 0
q133080 100 sl. 0 flows (1 buckets) sched 67544 weight 0 lmax 0 pri 0 droptail
sched 67544 type FIFO flags 0x0 16 buckets 1 active
BKT Prot Source IP/port_ Dest. IP/port Tot_pkt/bytes Pkt/Byte Drp
0 ip 0.0.0.0/0 0.0.0.0/0 6 346 0 0 0
02009: 300.000 Kbit/s 0 ms burst 0
q133081 100 sl. 0 flows (1 buckets) sched 67545 weight 0 lmax 0 pri 0 droptail
sched 67545 type FIFO flags 0x0 16 buckets 1 active
0 ip 0.0.0.0/0 0.0.0.0/0 352 389278 74 96540 0
02002: 300.000 Kbit/s 0 ms burst 0
q133074 100 sl. 0 flows (1 buckets) sched 67538 weight 0 lmax 0 pri 0 droptail
sched 67538 type FIFO flags 0x0 16 buckets 0 active
02003: 300.000 Kbit/s 0 ms burst 0
q133075 100 sl. 0 flows (1 buckets) sched 67539 weight 0 lmax 0 pri 0 droptail
sched 67539 type FIFO flags 0x0 16 buckets 0 active
02000: 300.000 Kbit/s 0 ms burst 0
q133072 100 sl. 0 flows (1 buckets) sched 67536 weight 0 lmax 0 pri 0 droptail
sched 67536 type FIFO flags 0x0 16 buckets 0 active
02001: 300.000 Kbit/s 0 ms burst 0
q133073 100 sl. 0 flows (1 buckets) sched 67537 weight 0 lmax 0 pri 0 droptail
sched 67537 type FIFO flags 0x0 16 buckets 0 active
02006: 300.000 Kbit/s 0 ms burst 0
q133078 100 sl. 0 flows (1 buckets) sched 67542 weight 0 lmax 0 pri 0 droptail
sched 67542 type FIFO flags 0x0 16 buckets 0 active
02007: 300.000 Kbit/s 0 ms burst 0
q133079 100 sl. 0 flows (1 buckets) sched 67543 weight 0 lmax 0 pri 0 droptail
sched 67543 type FIFO flags 0x0 16 buckets 0 active
02004: 300.000 Kbit/s 0 ms burst 0
q133076 100 sl. 0 flows (1 buckets) sched 67540 weight 0 lmax 0 pri 0 droptail
sched 67540 type FIFO flags 0x0 16 buckets 0 active
02005: 300.000 Kbit/s 0 ms burst 0
q133077 100 sl. 0 flows (1 buckets) sched 67541 weight 0 lmax 0 pri 0 droptail
sched 67541 type FIFO flags 0x0 16 buckets 0 activeSchedulers:
02008: 300.000 Kbit/s 0 ms burst 0
sched 2008 type WF2Q+ flags 0x0 0 buckets 0 active
02009: 300.000 Kbit/s 0 ms burst 0
sched 2009 type WF2Q+ flags 0x0 0 buckets 0 active
02002: 300.000 Kbit/s 0 ms burst 0
sched 2002 type WF2Q+ flags 0x0 0 buckets 0 active
02003: 300.000 Kbit/s 0 ms burst 0
sched 2003 type WF2Q+ flags 0x0 0 buckets 0 active
02000: 300.000 Kbit/s 0 ms burst 0
sched 2000 type WF2Q+ flags 0x0 0 buckets 0 active
02001: 300.000 Kbit/s 0 ms burst 0
sched 2001 type WF2Q+ flags 0x0 0 buckets 0 active
02006: 300.000 Kbit/s 0 ms burst 0
sched 2006 type WF2Q+ flags 0x0 0 buckets 0 active
02007: 300.000 Kbit/s 0 ms burst 0
sched 2007 type WF2Q+ flags 0x0 0 buckets 0 active
02004: 300.000 Kbit/s 0 ms burst 0
sched 2004 type WF2Q+ flags 0x0 0 buckets 0 active
02005: 300.000 Kbit/s 0 ms burst 0
sched 2005 type WF2Q+ flags 0x0 0 buckets 0 active -
@skveen said in The delay after enabling CP is very large:
It's not a wifi/ap problem, because there is no problem using other access points。
Wrong phrasing or you are contradicting yourself :
It is a AP/ wifi problem, as other AP work fine.
If it happens to just on one specific AP, remove this AP, and done.
Right ?When testing : use always cable connections. Don't use the radio (wifi). If your AP has a switch build in, hook up your test device to this switch.
If wifi exists, take the speed for granted. If you really want to see what happens on a radio waves level, you need to scan that. That needs special equipment to analyze the radio spectrum etc. Some APs can show you what they detect around them.You've introduced several possible factors then can be examined.
- You are using virtual nics ... it's a VM after all. Each VM hypervsior has its own particular config and settings. Go barebone, and suddenly ; no more issues ? : you know now you have to review your VM.
- Your captive portal is on its own separated LAN (OPT), right ?
- You have set limiters values, why ? Is your upstream/downstream quality (ISP) that bad that you need it ? Test with limiters, as they can do much good, but also much bad.
- Disable DNS Resolver and enable DNS forwarder : you are using the ancient dnsmasq, the forwarder ? Resolving, the default usage, isn't good for you ? Not that I think this will influence the bandwidth saturation your seeing.
Keep in mind : as soon as a captive portal user is authenticated, what happened is that the device of that user, MAC and IP, are put in a pass-firewall rule. Nothing more, nothing less. Traffic is handled like any other interface, with or without captive portal. Portal traffic does just something extra : pipes.
-
@Gertjan
Thank you for your replyIt's not a wifi/ap problem, because there is no problem using other access points。
This is what I expressed wrongly:It should be connected to other ssid (signal emitted by the same AP)When testing : use always cable connections. Don't use the radio (wifi). If your AP has a switch build >in, hook up your test device to this switch.
Because this hotspot is for wireless devices, I need to use a wireless device to test it- You are using virtual nics ... it's a VM after all. Each VM hypervsior has its own particular config >and settings. Go barebone, and suddenly ; no more issues ? : you know now you have to review >your VM.
- Your captive portal is on its own separated LAN (OPT), right ?
Use Interfaces/LAN (hn1),it is connected to the ap using the same vlan
(the other Interfaces is WAN/hn0)
Do I need to add an OPT interface for CP?
- You have set limiters values, why ? Is your upstream/downstream quality (ISP) that bad that you >need it ? Test with limiters, as they can do much good, but also much bad.
But i think it shouldn’t affect the intranet interface with pfsense. - Disable DNS Resolver and enable DNS forwarder : you are using the ancient dnsmasq, the >forwarder ? Resolving, the default usage, isn't good for you ? Not that I think this will influence the >bandwidth saturation your seeing.
Since client can't get internet using the DNS Resolver client, well, I tried using the default settings.
-
@skveen said in The delay after enabling CP is very large:
Since client can't get internet using the DNS Resolver client, well, I tried using the default settings.
Several things.
A captive portal can be used on the main pfSense LAN network, true.
I'm using it on a separate 'OPT1' interface, because a captive portal are typically a network with non trusted devices - you don't own them, you don't control them - you don't know who is using your portal, not what they are doing, etc. They are only there so they can use your Internet connection.
Also : keep the LAN for your trusted devices, or, why not, only for the pfSense GUI admin access, something that should be totally forbidden on the non trusted portal network.I use unbound, the resolver with the settings it had when I installed pfSense.
These settings were defined by Netgate. let's presume they know what's goof for pfSense, thus you and me.
My ISP, AFAIK, doesn't f*cck up my DNS requests, I'm allowed to use any DNS server on the planet, and that includes Internet's main 13 root servers, all the TLDs and of course every domain name server. My resolver resolves just fine.
So, no special knowledge is needed to make it work on the captive portal. No forwarding hassle.
There's one thing : you should allow UDP and TCP connection to port 53, to the portal NIC (pfSense) itself. That's where unbound listens for DNS requests.
Breaking DNS is the most known reason why the portal "doesn't work"'. See here : Troubleshooting Captive Portal.