Latency spikes during Filter reload - CE 2.6.0

-
@stephenw10 - output of pfctl -sr | wc -l is 1987. That command returns in about 1s
-
@stephenw10 - Which table reload command do you mean?
-
@stephenw10 - 1 table created.
128188/128188 addresses added.
0.29 real 0.12 user 0.16 sysfor time pfctl -t bogonsv6 -T add -f /etc/bogonsv6
-
Yes, that. And those times look fine.
You might also try:
[22.01-RELEASE][admin@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug 0.377u 0.329s 0:00.70 98.5% 208+187k 1+0io 0pf+0wHardly additional rules on that box though:
[22.01-RELEASE][admin@5100.stevew.lan]/root: pfctl -sr | wc -l 121Steve
-
@stephenw10 - time pfctl -f /tmp/rules.debug -> 6.06 real 0.35 user 5.70 sys
-
@stephenw10 - 0.370u 5.780s 0:06.15 100.0% 203+182k 5+0io 0pf+0w
-
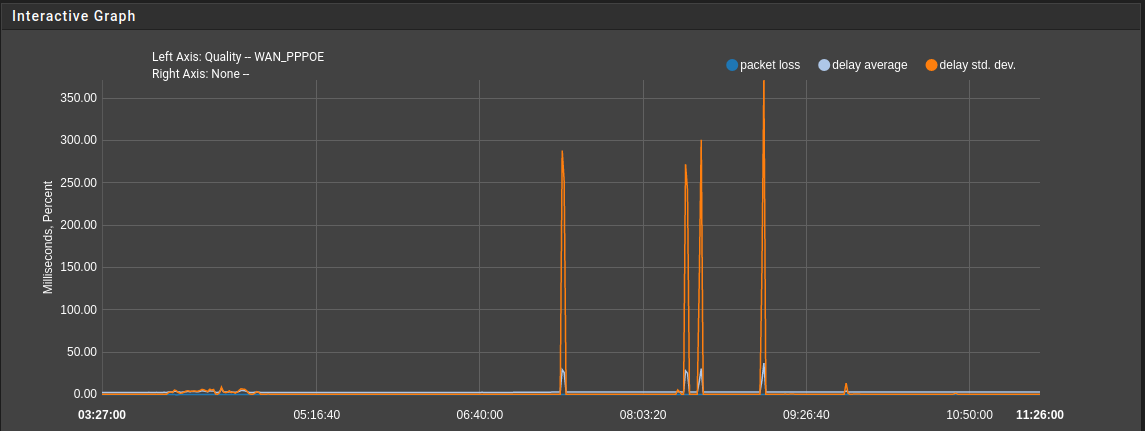
@stephenw10 - If it helps, I've restarted the pfSense and observed the stats. The WAN RTT was very high for ~50s after the GUI became available. The OpenVPN interfaces carried over the WAN connection gave normal RTT immediately.
-
@stephenw10 - And wireguard doesn't start after reboot. Having resaved the wireguard peers, the Gateways looked like
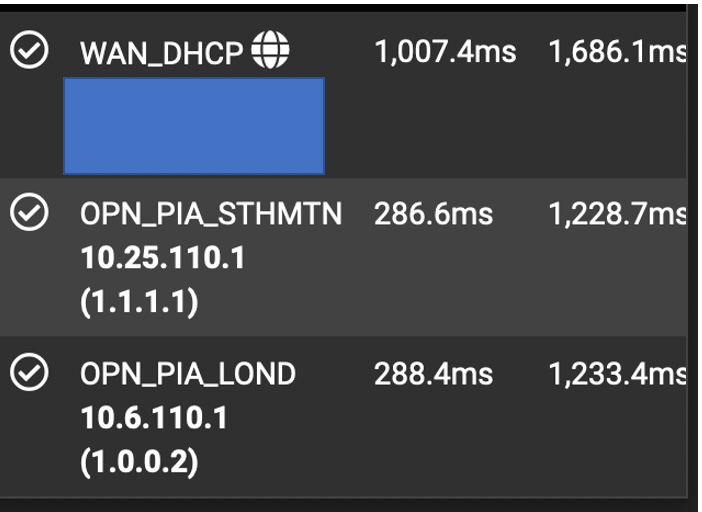
When all should be sub 10ms.
-
Hmm, those Wireguard stats are continually? Or for the 50s after boot?
6s to load the ruleset is pretty extreme too.
Testing here with a 1700 line ruleset and not seeing this. Still digging....
-
@stephenw10 - The stats above are for WAN and 2 OpenVPN interfaces, during the ~50s after Wireguard starts. I assume the rules are reloaded at that time? The other point I was making is that Wireguard won't start after reboot, until the WG peers have been disabled and re-enabled. I believe there's another thread somewhere on that topic. Wireguard was fine on 2.5.2
-
@stephenw10 - Here is the ThinkBroadband Monitor showing pre and post upgrade
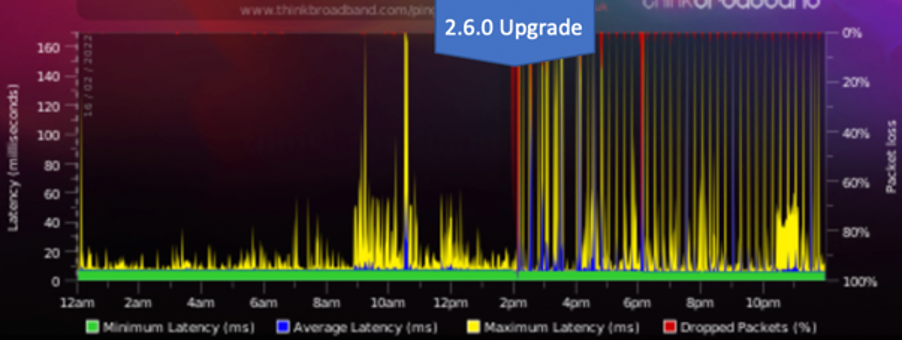
Stopping the rc.filter_configure_sync cron job running stops the latency spikes.
-
@stephenw10 said in Latency spikes during Filter reload - CE 2.6.0:
Testing here with a 1700 line ruleset and not seeing this. Still digging....
Maybe there is more to it than just rule count.
Do you have any Rules with advanced Options like State Type != keep or Gateway override for policy based routing? Do you use Gateway Groups in some rules?
-
@averlon - From memory,
-
State Type != keep -> no
-
Gateway groups -> yes
-
Gateway override -> yes
-
Also Traffic shaping -> yes
-
-
For Reference

Have currently only console access via IPMI. Gonna do some tests later, when I get in-band access to that machine.
-
@stephenw10 @averlon - as a test I disabled SMP by adding kern.smp.disabled=1 to /boot/loader.conf.local . Early indications are that this mitigates the latency issue. There was apparently a similar issue in 2.4.5 - https://forum.netgate.com/topic/149595/2-4-5-a-20200110-1421-and-earlier-high-cpu-usage-from-pfctl
-
Yes, though it isn't a regression of that issue directly as that was easy to replicate in the end.
Just to confirm you are seeing spikes pinging to the firewall or though it? Or Both?
-
@stephenw10 - I see both.
-
Ok, with a large generated ruleset I am able to see latency spikes when reloading it for the time it's loading.
But disabling does not make any difference. In fact it makes it significantly worse, which is what I'd expect.What values are you seeing there with only one CPU core?
Steve
-
@stephenw10 - I've not tested technically. It may be that the dashboard isn't show increased latency while the reload is running due to CPU spike. TBM is showing 15 min spikes, so I guess my early optimism is misplaced.
-
@stephenw10 - Having re-enabled SMP, I ran a continuous ping test from my PC to WAN address with 1000 byte payload. Steady state ping time is 4-5s. When reload is running, it results in 4 timeouts and 5-6 massively higher than normal ping times (1-5s vs 4-5ms), so actual period of high latency is ~10s.