BGP - K3S Kubernetes
-
Trying to build out a design to host a simple set of container hosting. Single server so I used K3s. I wanted to have automatic IP pools and route advertisement so I went with Cilium and BGP.
This is the first time for me to do this, so my root cause and debug are rather enemic for this.
Design:
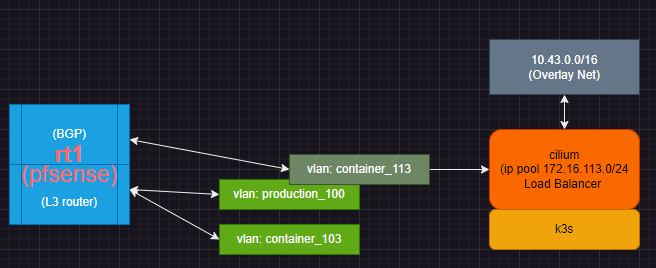
Server hosting k3s / cilum network configuration:
ubuntu 22.04
k3s single node install
cilium for LB, BGP, IP poolSetup on pfsense router side
Step15: BGP for K3S
Setup BGP for use by K3S on VLAN 103https://docs.ansible.com/ansible/latest/collections/kubernetes/core/k8s_module.html
Setup BGP on pfsense https://docs.netgate.com/pfsense/en/latest/packages/frr/bgp/example.html install service: frr Local AS: 65014 Remote AS: 65013 Container Tag: bgp-policy:pandora # all pods must have this tag added key:value
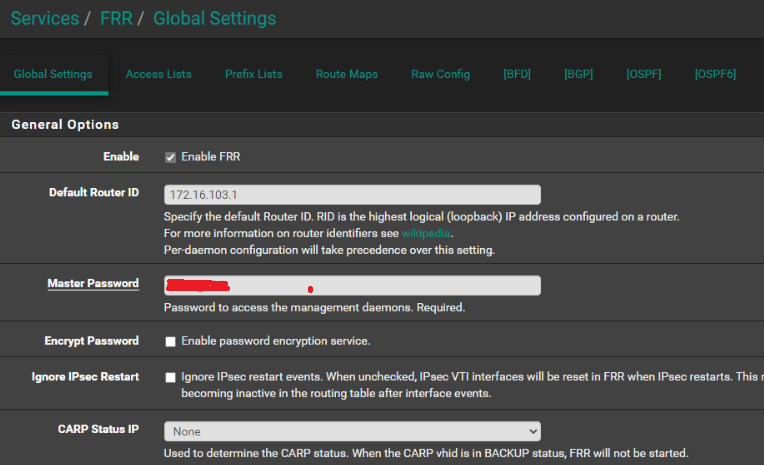
- I don't think this password is anwhere expected or used on client / server side. But this is not very clear what "master password" covers.
 rt0 bgp services
rt0 bgp services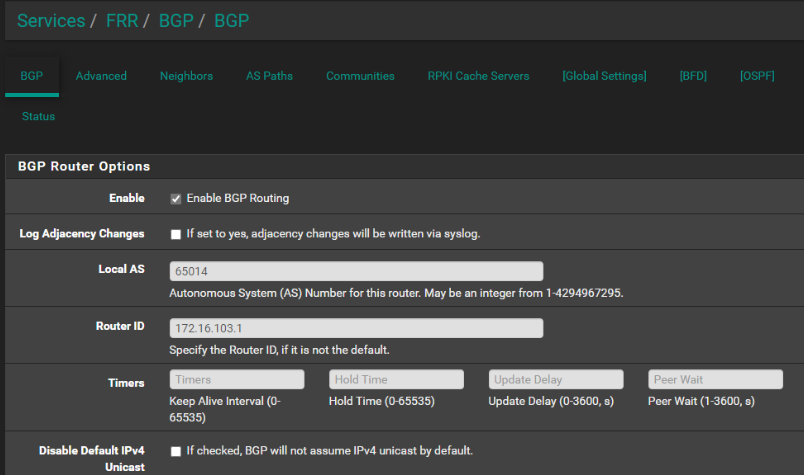 rt0 bgp map
rt0 bgp map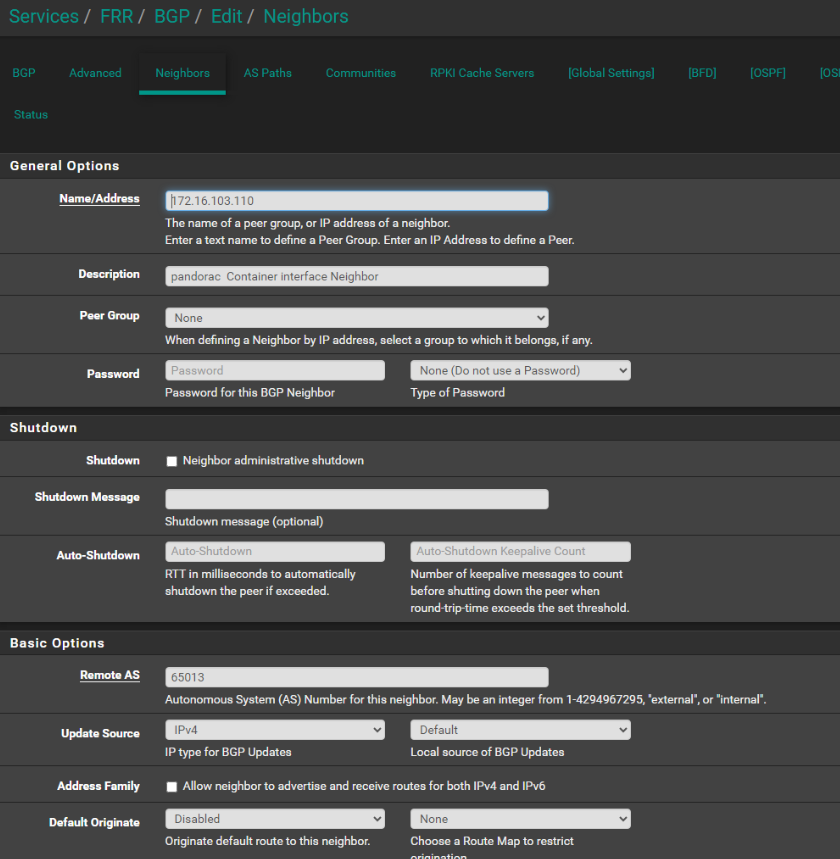
Review that services are showing up as type B --> BGP on router rt1 -> status -> frr and look for 103 subnet to have type B
Note Router BGP Status: Note state = Active
IPv4 Unicast Summary (VRF default):
BGP router identifier 172.16.103.1, local AS number 65014 vrf-id 0
BGP table version 0
RIB entries 0, using 0 bytes of memory
Peers 1, using 13 KiB of memoryNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
172.16.103.110 4 65013 0 0 0 0 0 never Active 0 pandorac ContainerTotal number of neighbors 1
BGP Active Check rt0 bgp neihbor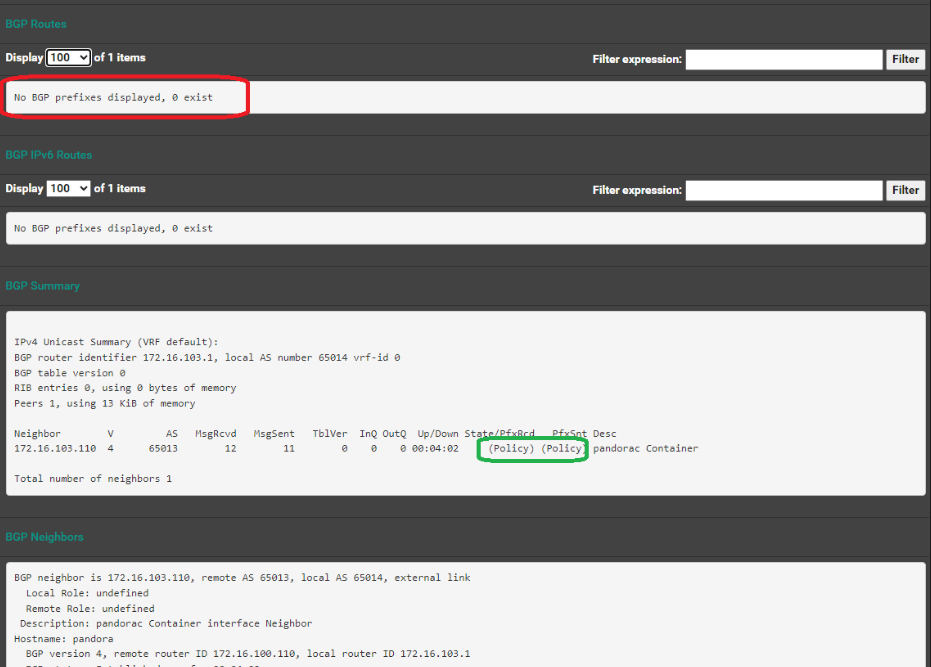 rt0 bgp neihbor
rt0 bgp neihborIssue: Deploy of container, where cilum does allocate IP, and setup route and LB mapping, the BGP does not display service on pfsense for broadcast
root@pandora:/media/md0/containers# kubectl get service -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 8h kube-system kube-dns ClusterIP 10.43.0.10 <none> 53/UDP,53/TCP,9153/TCP 8h kube-system metrics-server ClusterIP 10.43.59.241 <none> 443/TCP 8h kube-system hubble-peer ClusterIP 10.43.133.23 <none> 443/TCP 8h kube-system hubble-relay ClusterIP 10.43.129.105 <none> 80/TCP 8h kubernetes-dashboard kubernetes-dashboard ClusterIP 10.43.197.111 <none> 443/TCP 8h kube-system cilium-ingress LoadBalancer 10.43.152.213 172.16.113.72 80:30723/TCP,443:30333/TCP 8h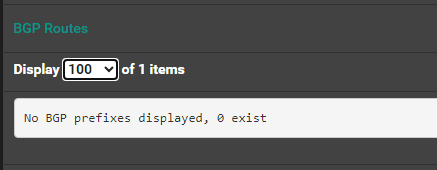
Question:
- Am i missing step for above setup of bgp
- what tools or steps can I do to debug where my host is registering as a peer, but services are not being populated
-
That
(Policy)in the status implies the routes are blocked by the policy. Did you apply the allow-all route map to the neighbour? -
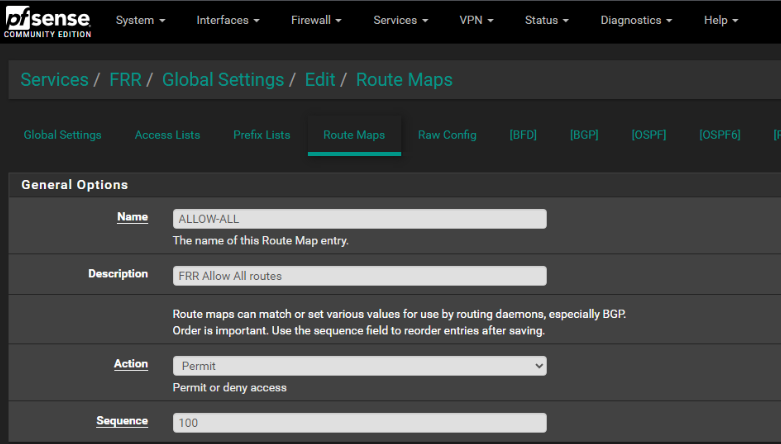
Unless there is more to the settings then noted in above image
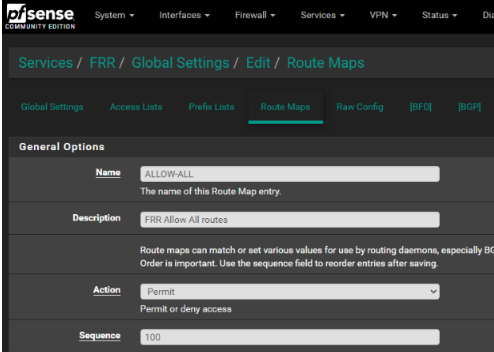
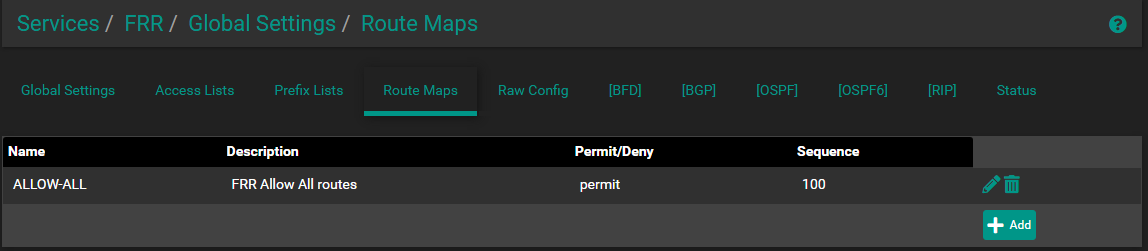
I believe, that is an allow map updates from ALL for ALL . Not sure what sequence 100 maps to ... but seems to match directions
-
Yes but you have to apply that route map to the neighbour in question:

https://docs.netgate.com/pfsense/en/latest/packages/frr/bgp/config-neighbor.html#peer-filtering
-
I think that was the peice missing. Your image noted a field "Route Map Filter" But the image did not note context, and I poked around and made two below changes:
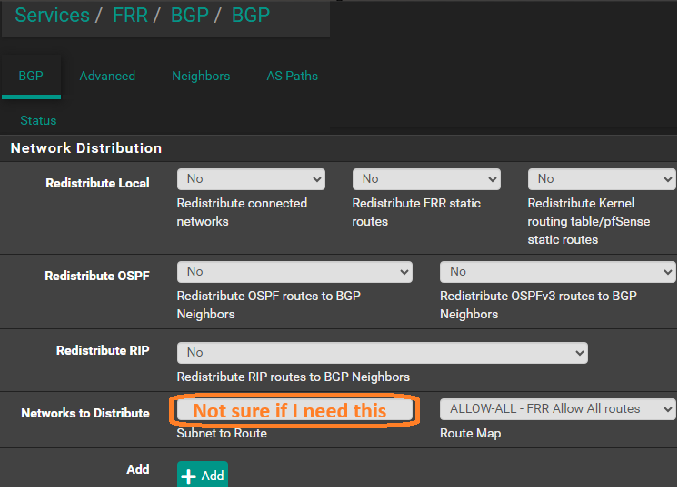
and I also set
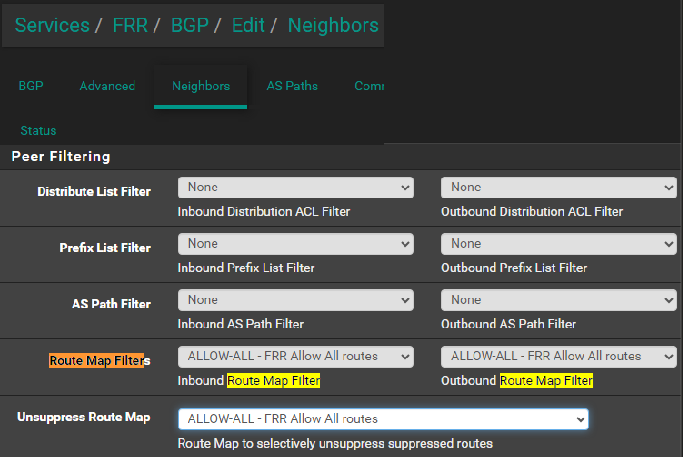
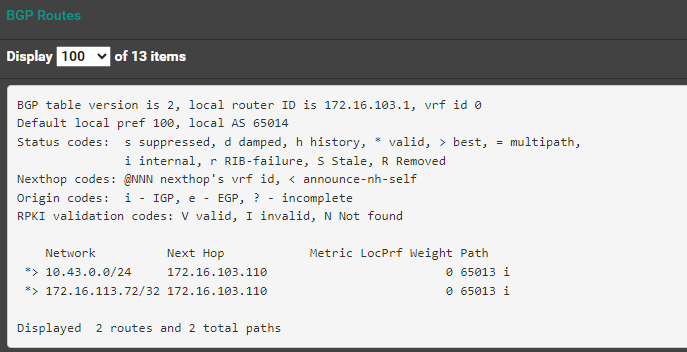
Now BGP routes display
root@pandora:~# kubectl get services -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 2d4h kube-system kube-dns ClusterIP 10.43.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d4h kube-system metrics-server ClusterIP 10.43.59.241 <none> 443/TCP 2d4h kube-system hubble-peer ClusterIP 10.43.133.23 <none> 443/TCP 2d4h kube-system hubble-relay ClusterIP 10.43.129.105 <none> 80/TCP 2d4h kubernetes-dashboard kubernetes-dashboard ClusterIP 10.43.197.111 <none> 443/TCP 2d4h kube-system cilium-ingress LoadBalancer 10.43.152.213 172.16.113.72 80:30723/TCP,443:30333/TCP 2d4h -
Update:
So it seems the router is broadcasting, and what seems to map to deployments do updates.
I did a test deploy of test wordpress website and it seems to have setup IPLB services that propogate through BGP:
default my-wordpress-mariadb ClusterIP 10.43.21.226 <none> 3306/TCP 116s default my-wordpress LoadBalancer 10.43.72.205 172.16.113.176 80:31905/TCP,443:30186/TCP 116srouter frr BGP
BGP table version is 3, local router ID is 172.16.103.1, vrf id 0 Default local pref 100, local AS 65014 Status codes: s suppressed, d damped, h history, * valid, > best, = multipath, i internal, r RIB-failure, S Stale, R Removed Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self Origin codes: i - IGP, e - EGP, ? - incomplete RPKI validation codes: V valid, I invalid, N Not found Network Next Hop Metric LocPrf Weight Path *> 10.43.0.0/24 172.16.103.110 0 65013 i *> 172.16.113.72/32 172.16.103.110 0 65013 i *> 172.16.113.176/32 172.16.103.110 0 65013 i Displayed 3 routes and 3 total pathsAnd if I launch webpage from the hosting system (172.16.103.110) running k3s I get
admin@pandora:~$ curl -Is http://172.16.113.176 HTTP/1.1 200 OK Date: Mon, 08 Jan 2024 17:12:29 GMT Server: Apache Link: <http://172.16.113.176/wp-json/>; rel="https://api.w.org/" Content-Type: text/html; charset=UTF-8host route table
admin@pandora:~$ route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default rt1.penguinpage 0.0.0.0 UG 427 0 0 br100 10.43.0.0 10.43.0.192 255.255.255.0 UG 0 0 0 cilium_host 10.43.0.192 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host link-local 0.0.0.0 255.255.0.0 U 1000 0 0 nm-bond 172.16.100.0 0.0.0.0 255.255.255.0 U 427 0 0 br100 172.16.101.0 0.0.0.0 255.255.255.0 U 428 0 0 br101 172.16.102.0 0.0.0.0 255.255.255.0 U 426 0 0 br102 172.16.103.0 0.0.0.0 255.255.255.0 U 425 0 0 br103 admin@pandora:~$So host is not aware of 172.16.113.0/24 segment outside the router helping
But remote from other subnets I get nothing.
Ex: Windows system on 172.16.100.0/24
C:\Users\user1>curl -o curl -Is http://172.16.113.176 C:\Users\user1>But if I add static route.. things start working
route -p ADD 172.16.113.0 MASK 255.255.255.0 172.16.103.110 METRIC 1 PS C:\Users\Jerem> curl http://172.16.113.176 StatusCode : 200 StatusDescription : OK Content : <!DOCTYPE html> <html lang="en-US"> <head>So this implies that :
- That the target k3s node understands routing and route return working and via BGP
- That its not a firwall issue
- the pfsense router is not handling routing to this subnet for other subnets Ex: VLAN 100 nodes
Only thing I found odd is the route table out of FRR -> Status -> Zebra
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF, I - IS-IS, B - BGP, E - EIGRP, T - Table, v - VNC, V - VNC-Direct, A - Babel, f - OpenFabric, > - selected route, * - FIB route, q - queued, r - rejected, b - backup t - trapped, o - offload failure K>* 0.0.0.0/0 [0/0] via 108.234.144.1, igc0, 3d01h34m C>* 10.10.10.1/32 [0/1] is directly connected, lo0, 3d01h34m B>* 10.43.0.0/24 [20/0] via 172.16.103.110, igc1.103, weight 1, 16:36:31 C>* 108.234.144.0/22 [0/1] is directly connected, igc0, 3d01h34m C>* 172.16.100.0/24 [0/1] is directly connected, igc1.100, 17:01:52 C>* 172.16.101.0/24 [0/1] is directly connected, igc1.101, 17:01:52 C>* 172.16.102.0/24 [0/1] is directly connected, igc1.102, 17:01:52 S 172.16.103.0/24 [1/0] via 172.16.103.110 inactive, weight 1, 17:01:52 C>* 172.16.103.0/24 [0/1] is directly connected, igc1.103, 17:01:52 C>* 172.16.104.0/24 [0/1] is directly connected, ovpns1, 3d01h34m C>* 172.16.110.0/24 [0/1] is directly connected, igc1.110, 17:01:52 C>* 172.16.111.0/24 [0/1] is directly connected, igc1.111, 17:01:52 C>* 172.16.112.0/24 [0/1] is directly connected, igc1.112, 17:01:52 B>* 172.16.113.72/32 [20/0] via 172.16.103.110, igc1.103, weight 1, 16:36:31 B>* 172.16.113.176/32 [20/0] via 172.16.103.110, igc1.103, weight 1, 01:39:17 C>* 172.16.120.0/24 [0/1] is directly connected, igc1.120, 17:01:52 C>* 172.16.121.0/24 [0/1] is directly connected, igc1.121, 17:01:52 C>* 172.16.122.0/24 [0/1] is directly connected, igc1.122, 17:01:52 C>* 172.16.130.0/24 [0/1] is directly connected, igc1.130, 17:01:52 C>* 172.16.131.0/24 [0/1] is directly connected, igc1.131, 17:01:52 C>* 172.16.132.0/24 [0/1] is directly connected, igc1.132, 17:01:52My guess is there is yet another configuration setting I need to do for BGP to forward properly from intranets.
-
So you're adding that static route to the external system directly?
Sounds like the client is just not using pfSense as it's default route. Or whatever it is using as that cannot hairpin the route back to pfSense possibly.
Or it's creating an asymmetric route; check the firewall logs.
-
Yes..
Windows laptop yes it can get to internet and all other subnets... (ex: SSH into k3s node and run above tests)
route -p ADD 172.16.113.0 MASK 255.255.255.0 172.16.103.110 METRIC 1As a baseline I have another VM on that same VLAN as the laptop and it cannot get to the subnet (aka did not run above route add command)
So to me this means this is a misconfiguration within the pfsense that when my hosts (windows) attempt to find resource on 172.16.113.0 (per curl test) it goes to my default GW 172.16.100.1/24 and it should then forward down 172.16.103.110 to get to cilium 172.16.113.176.
If it was issue related to hairpin.. I think it would also fail on nodes within 172.16.103.0/24 also failing.. but they (as noted in test) can resolve 172.16.113.176.
-
Yes I would expect it to work if that traffic is going via pfSense.
Try a traceroute.
Check the states when you try to ping.
What's actually happening when it doesn't have that static route?
-
Traceroute would require ICMP mapping and services.
I did it just for baseline from Linux host direct (which can get to website without route add) . no response. As well as from windows host with route add.. also no response.
That is why trying to get debug out of pfsense as to where packets "work when from 172.16.103.110" and with Route add "172.16.100.32"
But fail from 172.16.100.22
packetcapture-igc1.103-20240108164045.pcap
I also tried to add networks for distribtution in but no change
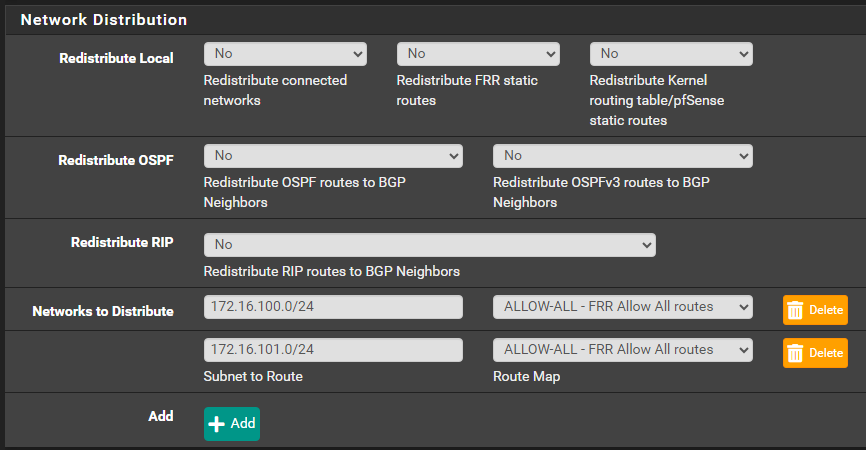
Just seems like the pfsense router is just not routing packets to known subnet .. but only from specific networks
-
Adding a static route to the windows client changes nothing in how pfSense routes that traffic. It has to be in the client itself.
-
Not sure what you mean.
If my systems (windows / linux) are on 172.16.100.0/24 and know nothing of how to route to 172.16.113.0/24, they just use Default GW 172.16.100.1 which is pfsense.
Route (pfsense) then refers to its table, and based on BGP knows path to get to 172.16.113.0/24 is via 172.16.103.110.
PS C:\Users\user> route -p delete 172.16.113.0 MASK 255.255.255.0 172.16.103.110 METRIC 1 OK! PS C:\Users\user> route -p add 172.16.113.0 MASK 255.255.255.0 172.16.100.1 METRIC 1 OK! PS C:\Users\user> curl 172.16.113.176 # --> timeout PS C:\Users\user> route -p delete 172.16.113.0 MASK 255.255.255.0 172.16.100.1 METRIC 1 OK! PS C:\Users\user> route -p add 172.16.113.0 MASK 255.255.255.0 172.16.103.110 METRIC 1 OK! PS C:\Users\user> curl 172.16.113.176 StatusCode : 200 StatusDescription : OK Content : <!DOCTYPE html> <html lang="en-US"> <head> -
OK how does the client know how to reach 172.16.103.110? That must also be via pfSense at 172.16.100.1 right?
-
Yes
Route table from pfsense:
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF, I - IS-IS, B - BGP, E - EIGRP, T - Table, v - VNC, V - VNC-Direct, A - Babel, f - OpenFabric, > - selected route, * - FIB route, q - queued, r - rejected, b - backup t - trapped, o - offload failure K>* 0.0.0.0/0 [0/0] via 108.234.144.1, igc0, 4d02h15m C>* 10.10.10.1/32 [0/1] is directly connected, lo0, 4d02h15m B>* 10.43.0.0/24 [20/0] via 172.16.103.110, igc1.103, weight 1, 1d17h17m C>* 108.234.144.0/22 [0/1] is directly connected, igc0, 4d02h15m C>* 172.16.100.0/24 [0/1] is directly connected, igc1.100, 1d17h42m C>* 172.16.101.0/24 [0/1] is directly connected, igc1.101, 1d17h42m C>* 172.16.102.0/24 [0/1] is directly connected, igc1.102, 1d17h42m S 172.16.103.0/24 [1/0] via 172.16.103.110 inactive, weight 1, 1d17h42m C>* 172.16.103.0/24 [0/1] is directly connected, igc1.103, 1d17h42m C>* 172.16.104.0/24 [0/1] is directly connected, ovpns1, 4d02h15m C>* 172.16.110.0/24 [0/1] is directly connected, igc1.110, 1d17h42m C>* 172.16.111.0/24 [0/1] is directly connected, igc1.111, 1d17h42m C>* 172.16.112.0/24 [0/1] is directly connected, igc1.112, 1d17h42m B>* 172.16.113.72/32 [20/0] via 172.16.103.110, igc1.103, weight 1, 1d17h17m B>* 172.16.113.176/32 [20/0] via 172.16.103.110, igc1.103, weight 1, 1d02h20m C>* 172.16.120.0/24 [0/1] is directly connected, igc1.120, 1d17h42m C>* 172.16.121.0/24 [0/1] is directly connected, igc1.121, 1d17h42m C>* 172.16.122.0/24 [0/1] is directly connected, igc1.122, 1d17h42m C>* 172.16.130.0/24 [0/1] is directly connected, igc1.130, 1d17h42m C>* 172.16.131.0/24 [0/1] is directly connected, igc1.131, 1d17h42m C>* 172.16.132.0/24 [0/1] is directly connected, igc1.132, 1d17h42m -
So what did the states show when you try to open it without the static route on the client?
Looking at the pfSense routing table I wonder if the inactive more specific route to 172.16.103.0/24 is causing a problem.

-
Could be...
But.......
Why when I add route to host... does it start working?
Why when from the hosting system can I (without adding route) get to site? -
I'd still be checking the states and/or running an ping and pcaps to see where that is actually being sent.
-
Just to close this out and also post what I learned.
Root cause: Server with multiple interfaces, where BGP and cilium are binding to the NOT default interface,, will never work.
Ex:
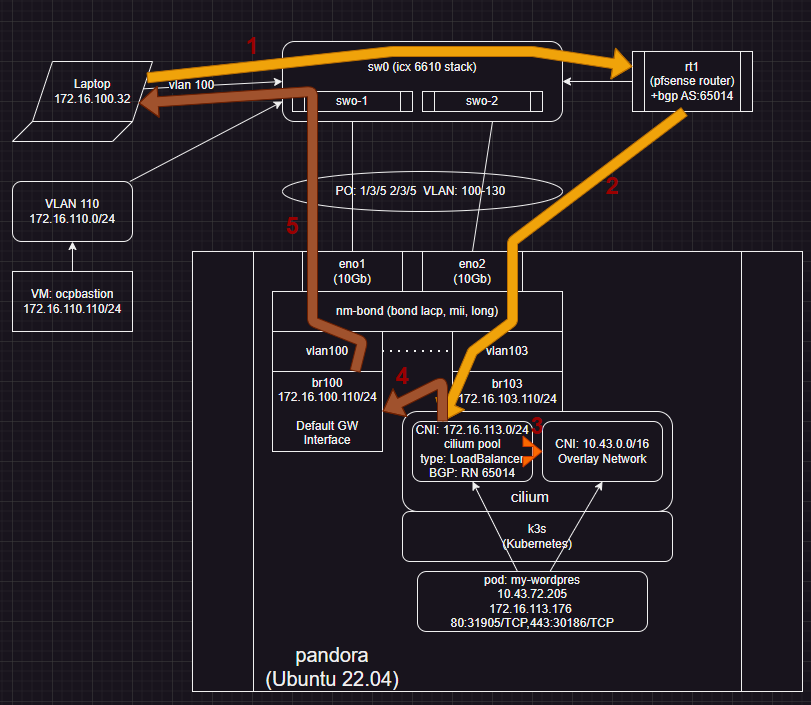
Idea was to have VLAN 103 for all containers.. used by various K8 clusters.... but.. Cilium returns routes based on underlying Linux .. which follows DGW through 172.16.100... which confuses hosts waiting for packets to return from pfsense 172.16.103.1
Working design:
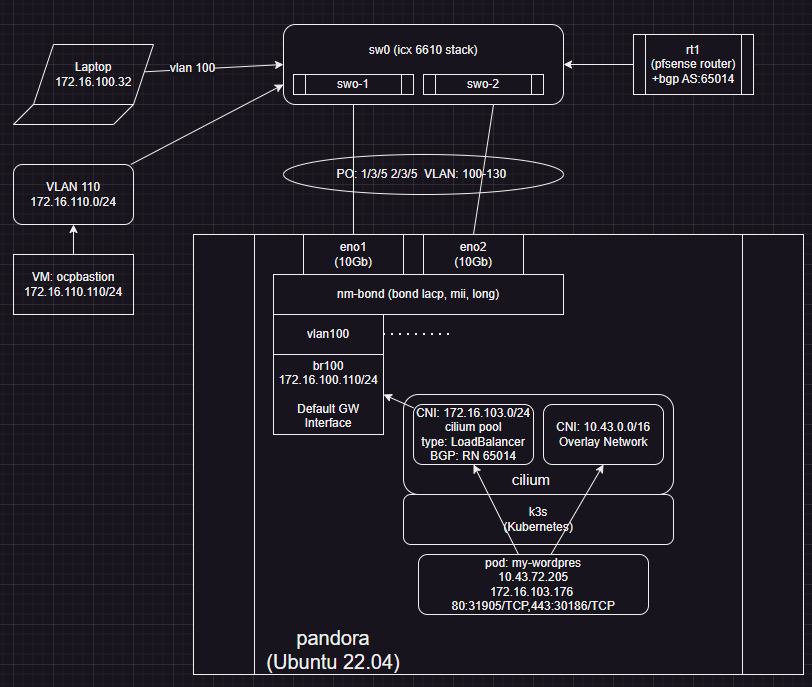
Change:
- remove all L2/3 subnet for 172.16.103.0
- setup within CNI (Cilium) that its IP pool is now 172.16.103.0/24
- redirect all bgp through host with bound DGW 172.16.100.110 with bgp neighbor definition to 172.16.100.1 (pfsense)
Now BGP does not take weird packet paths etc.
How I root cause.: Watch packet sessions on host:
tcpdump -i br103 -s 0 'tcp port http'then
tcpdump -i br100 -s 0 'tcp port http'
Then from laptop
curl http://172.16.113.176what I saw was packets in (10x due to fail return)... on both interfaces... which means return was out different interface.
Thanks for those who helped respond and posting. Hope this helps others not shave the same yak.
-
Nice catch.

-
@penguinpages can you share your cilium bgp peering policy? I’d like to see what it looks like. I am having the same problem. I use almost the same equipment you have - I have a pfsense doing bgp, a brocade icx7250 doing layer 3 routing ( all my vlans are setup here ) and I have a server with 2 nics. I cant connect to a test nginx demo i have setup on my kubernetes cluster with cilium.